
从逻辑角度来说,数组和链表都是线性结构(就是排成一条线的结构,只有前后两个方向,非线性结构包括树、图等,后面会讲到),从存储角度来说,一个是顺序存储,一个是链式存储,各有利弊。
数组需要预先申请连续内存,超出限制会溢出,但是对明确知道规模的小型数据集而言,使用数组会更加高效,随机访问的特性也更加方便数组读取,但插入和删除性能要差一些;链表的话没有空间限制,但是需要额外空间存储指针,插入、删除效率很高,但不支持随机访问。
接下来我们要介绍两种特殊的线性结构,或者说用于满足特定场景需求的线性结构:栈和队列。
首先来看栈。
栈的概念
栈(Stack)又叫堆栈,是限定只能在一端进行插入和删除操作的线性表,并且满足后进先出(LIFO)的特点,即最后插入的最先被读取。我们把允许插入和删除的一端叫做栈顶,另一个端叫做栈底,不含任何数据的栈叫做空栈。
栈的概念比较简单,理解起来也不复杂,下面给出一个图示,帮助你形象了解栈的操作流程:
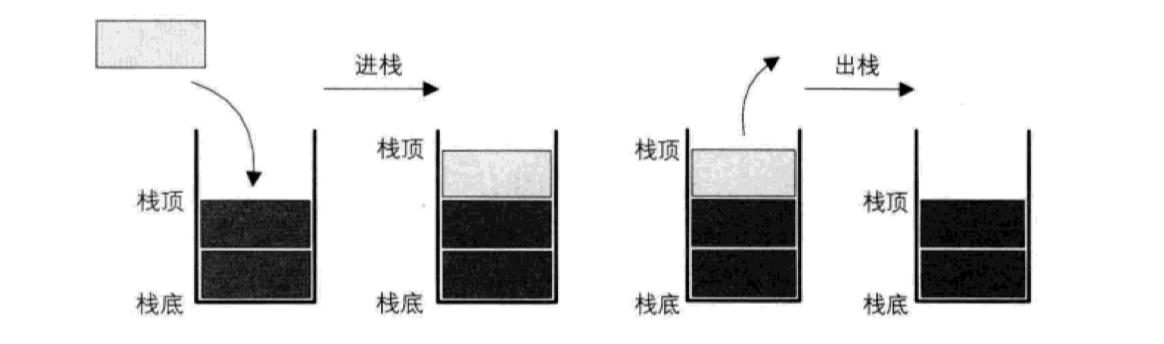
我们将插入操作叫做进栈,读取(删除)操作叫做出栈。
栈的实现
栈支持通过数组或链表实现,通过数组实现的通常叫做顺序栈,通过链表实现的叫做链栈。通过链表实现没有空间限制,并且插入和删除元素的效率更高,显然更加合适一些,下面我们基于 Go 语言来实现一个简单的链栈。
链栈本质上就是一个特殊的链表,特殊之处在于只能从头部插入节点,然后从头部读取(并删除)节点,因此实现起来非常简单,我们为这个栈提供了进栈、出栈和遍历功能:
package main
import (
"fmt"
)
// 定义链表节点
type Node struct {
Value int
Next *Node
}
// 初始化栈结构(空栈)
var size = 0
var stack = new(Node)
// 进栈
func Push(v int) bool {
// 空栈的话直接将值放入头节点即可
if stack == nil {
stack = &Node{v, nil}
size = 1
return true
}
// 否则将插入节点作为栈的头节点
temp := &Node{v, nil}
temp.Next = stack
stack = temp
size++
return true
}
// 出栈
func Pop(t *Node) (int, bool) {
// 空栈
if size == 0 {
return 0, false
}
// 只有一个节点
if size == 1 {
size = 0
stack = nil
return t.Value, true
}
// 将栈的头节点指针指向下一个节点,并返回之前的头节点数据
stack = stack.Next
size--
return t.Value, true
}
// 遍历(不删除任何节点,只读取值)
func traverse(t *Node) {
if size == 0 {
fmt.Println("空栈!")
return
}
for t != nil {
fmt.Printf("%d -> ", t.Value)
t = t.Next
}
fmt.Println()
}
func main() {
stack = nil
// 读取空栈
v, b := Pop(stack)
if b {
fmt.Print(v, " ")
} else {
fmt.Println("Pop() 失败!")
}
// 进栈
Push(100)
// 遍历栈
traverse(stack)
// 再次进栈
Push(200)
// 再次遍历栈
traverse(stack)
// 批量进栈
for i := 0; i < 10; i++ {
Push(i)
}
// 批量出栈
for i := 0; i < 15; i++ {
v, b := Pop(stack)
if b {
fmt.Print(v, " ")
} else {
// 如果已经是空栈,则退出循环
break
}
}
fmt.Println()
// 再次遍历栈
traverse(stack)
}
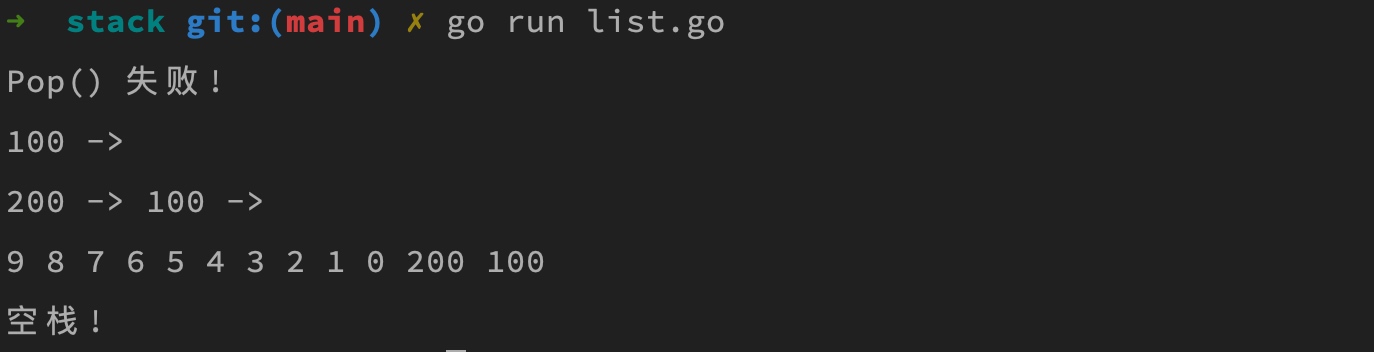
运行上述代码,打印结果如下:
感兴趣的同学可以自行通过 Go 语言的数组/切片实现一个顺序栈。
栈的使用场景
栈在日常开发和软件使用中,应用非常广泛,比如我们的浏览器前进、倒退功能,编辑器/IDE 中的撤销、取消撤销功能,程序代码中的函数调用、递归、四则运算等等,都是基于栈这种数据结构来实现的,就连著名的 stackoverflow 网站也是取栈溢出,需要求教之意。



学院君,stack = stack.Next //将栈的头节点指针指向下一个节点
这种操作内存会被回收么,是不是引用计数为0的数据就会被回收掉了