
极客智坊图片对话功能已经合并到万能答题统一入口,新的入口点击这里查看。
上周 OpenAI 发布了预览版 GPT-4-Vision,于是这个周末我抽空基于 GPT-4V 为极客智坊新增了图片对话功能,顺便把阿里通义千问VL也整合进来(限时免费)作为 Backup 方案。
GPT-4 Vision(GPT-4V)在现有的 GPT-4 功能基础上进行了扩展,除了原有的文本交互功能外,还增加了视觉分析功能,因此它是一种多模态模型,允许用户上传图像作为输入,并与模型进行对话,GPT-4V 擅长基于图形的学术研究、数据分析、数学推理、Web开发、以及创意内容生成,但目前预览版仍有一些不足,比如不支持医学图像,最大输出字符限制在4096个,以及对非英语语言支持还没有调到最优(尽管已经非常强大)。
出于安全原因,GPT-4V不支持验证码识别。
更多细节网上有很多,我这里不深入展开,我的职责是把 GPT-4V 落地为可用服务助力大家的学习、工作、生活,所以接下来,我来简单给大家介绍下如何在极客智坊中使用 GPT-4V 进行图片对话。
打开极客智坊网站,进入万能答题页面,可以看到现在右侧顶部区域新增了一个图片对话入口:
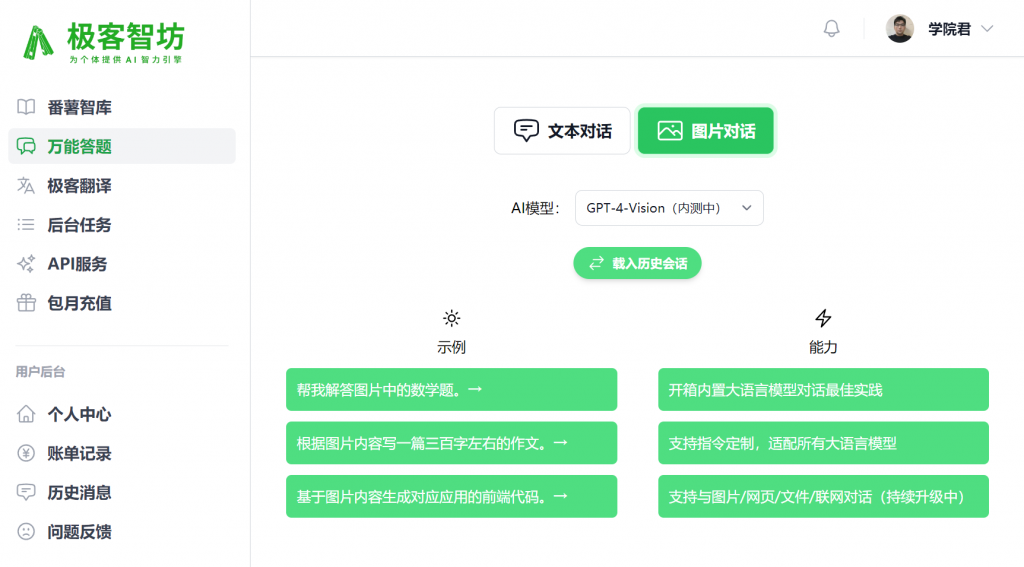
点击即可进入图片对话界面,在AI模型中选择你希望对话的AI模型:

然后在输入框点击图片按钮上传图片,输入你的问题或需求,点击提交即可开启和该图片的对话:


当然,我还选了几个典型场景作为示例案例,你直接点击然后提交即可快速预览 GPT-4V 的强大功能:

最后 GPT-4V 成功给出了正确答案 —— 30:

如果你对 GPT-4V 感兴趣的话立即去体验一下吧:
立即体验上述新功能特性:点击前往极客智坊图片对话。




[…] 图片对话已经迁移到专门的图片对话功能,基于GPT-4V等多模态模型实现。 […]