主要的软件设计原则
软件设计原则指导开发人员创建高效、可扩展和可维护的软件。通过遵循这些原则,开发人员可以创建易于阅读、测试和扩展的代码,降低总体拥有成本,并使团队有效合作更加容易。
以下是一些最基本的软件设计原则列表:
- 关注点分离:您的应用程序应该被分成具有少量功能重叠的离散特性。减少交互位置对于实现强内聚和低耦合至关重要。即使在功能内部的封闭性不会显著重叠的情况下,将功能在不恰当的边界上分开可能会导致特性之间的过度耦合和复杂性。
- 面向对象编程原则
- 封装:将操作数据的方法与数据捆绑在一起。它限制了对对象组成部分的直接访问,防止意外干扰和滥用数据。
- 抽象:使用简单的类来代表复杂性。它隐藏了复杂的实现细节,只展示必要的部分。
- 继承:这允许一个类(子类)从另一个类(父类)中继承属性和行为(方法)。
- 多态:这使得一个实体可以被视为一个通用类别,从而使其可以采用多种形式。例如,一个特定的类可以被视为其父类或其中一个实现的接口。
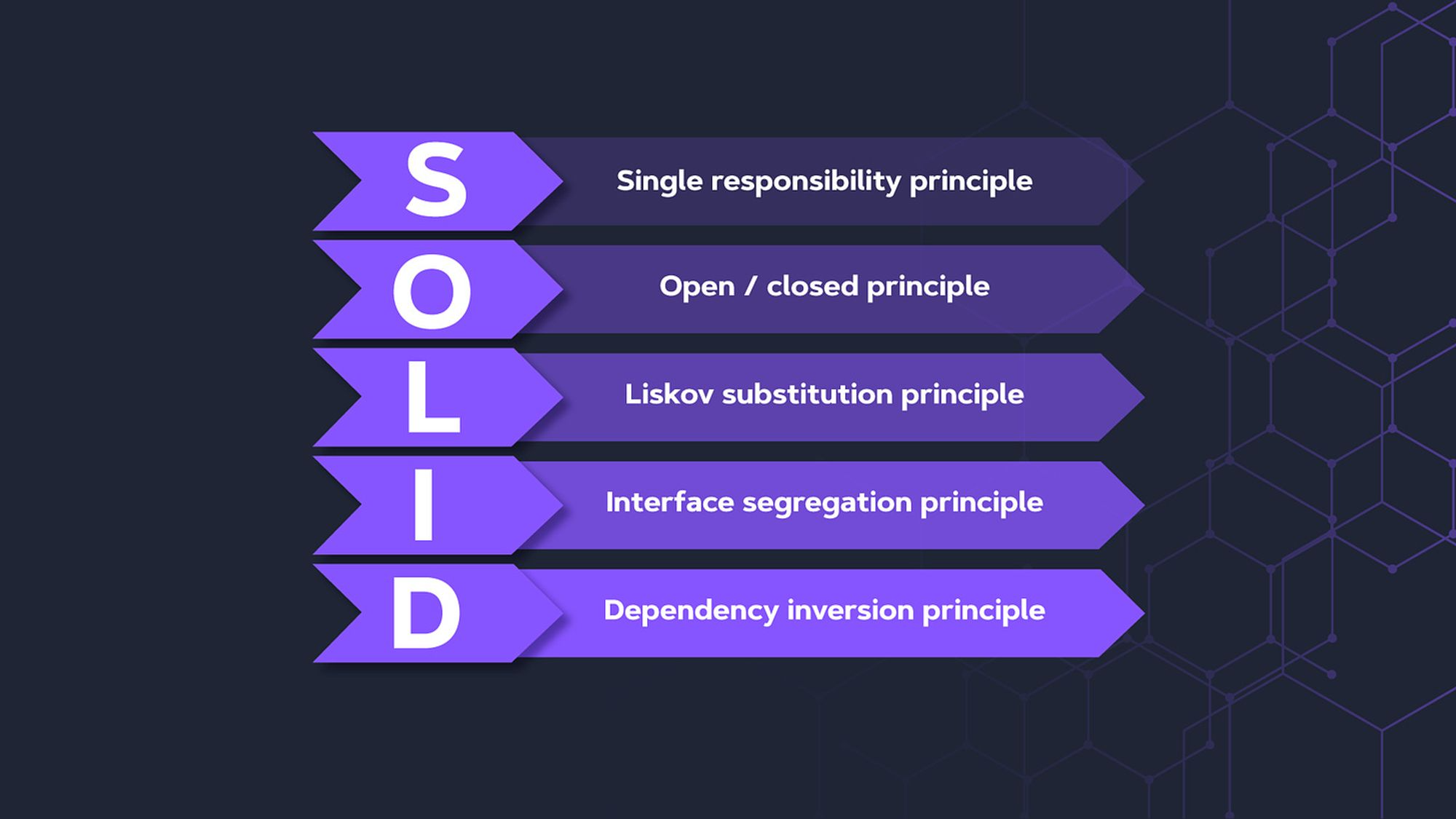
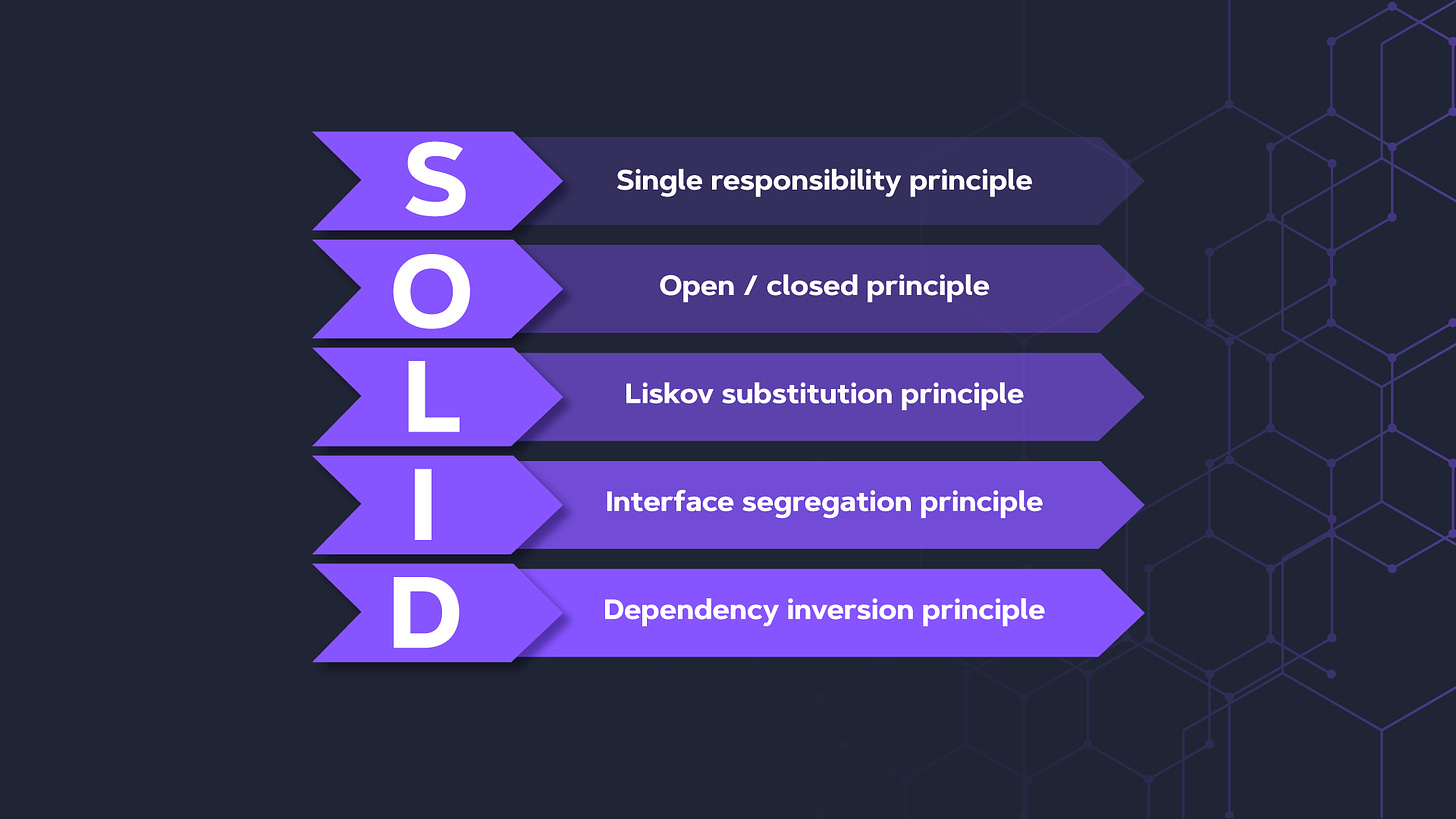
- SOLID原则设计原则指导开发人员创建可维护、可扩展和高效的面向对象软件系统。
- 单一责任原则(SRP):一个类/服务/API只应该有一个变化的原因,也就是说,它只应该有一个工作或责任。
- 开闭原则(OCP):软件实体(类、模块、函数等)应该对扩展开放,对修改封闭。这意味着你可以在不改变现有代码的情况下添加新的功能。
- 里氏替换原则(LSP):它规定可以使用任何子类来替代父类,并且可以期望它能正确地工作。这意味着如果将一个派生类(子类)类型传递给一个使用基类类型的程序,它仍然可以工作而不知道它是子类类型。
- 接口隔离原则(ISP):一个类不应被迫实现它不使用的接口。这意味着为每个类创建特定的接口,而不是拥有一个大而全的接口。
- 依赖倒置原则(DIP):高层模块不应依赖于低层模块。抽象应该独立于详细信息,而详细信息应该依赖于抽象。这意味着你应该依赖于抽象而不是具体的实现。
- 不要重复自己(DRY):避免代码中的重复,这可能会导致不一致和错误。重用代码而不是复制代码。然而,在某些情况下,复制可能更好。
- 保持简单、傻瓜(KISS):保持代码简单明了,简单的代码更容易理解和维护,并且更不容易出错。
- YAGNI(你不会需要它):避免通过仅在需要时添加功能来增加不必要的复杂性。在某些情况下,如果开发成本非常昂贵或存在重大设计失败,您可能需要支付预先、全面的设计和测试费用。如果应用程序要求不明确或您预期设计会随时间改变,则不要过早进行大量的设计工作。
- Demeter法则(LoD)或最少知识原则:对象只应与直接朋友进行通信,而不应了解其他对象的内部工作。
- 组合优于继承:优先使用对象组合而不是类继承,因为它更加灵活,并帮助避免与更大的继承层次结构相关的问题。
- 最小惊讶原则或最少惊奇原则表示系统应该以最不令人惊讶或混淆的方式行事(即,它应该按照大多数用户的预期行事)。例如,如果您有一个用户账户服务,更新用户数据应该使用
UpdateUserData()方法。错误的方法可能是一个名为RebuildUserData()的方法。
腐烂软件的七种设计异味
我们都希望在设计和实现软件时能够尽善尽美。随着软件的增长,设计和架构变得越来越大而复杂,因为软件不断演化。在此期间,技术债务往往会积累,使得我们的软件维护难度增加,容易出现错误。
根据Robert C. Martin,以下是一些糟糕架构的症状:
- 僵化性:僵化的软件很难适应变化,因为即使进行一次修改,也必然会导致其他更改的必要性。当我们以为工作快要完成时,我们会发现还有其他需要更新的代码,使我们进入一条看不到出口的兔子洞。
- 脆弱性:脆弱的软件经常在单一变化导致的情况下频繁出现故障。通常,问题出现在与变化环境无关的位置。随着模块的脆弱性增加,一个变化可能导致无法预料的问题的概率趋近于确定性。
- 不可移植性:当一个设计中的组件可以在不同系统中使用,但需要太多工作和风险时,它被认为是不可移植的。不幸的是,这是一个相当常见的情况。
- 粘度:此时,维护软件架构变得困难。做正确的事情比做错误的事情(破坏架构)更加困难。维护软件架构的设计应该更加简单。
- 不必要的复杂性:这可能是糟糕设计最明显的证据。开发人员为了避免其他六种臭味,创造了许多抽象,并对预期的未来更改做了规划。优秀的软件是轻量级、灵活的,易于阅读和理解,最重要的是,易于修改,因此您不必考虑未来的修改(YAGNI原则)。复杂度度量指标可以帮助诊断此问题。
- 重复代码:当架构具有应该统一到单个抽象下的代码结构时,会发生重复。当存在重复代码时,修改软件变得困难。当发现重复代码中的错误时,必须在每个实例中进行更正。然而,每次迭代都可能有些差异。
- 晦涩难懂:晦涩难懂指的是模块很难理解。代码可以分为两种形式:明确和表达性的,或者晦涩和神秘的。随着时间的推移,代码通常变得更难理解。我们通常需要深入实现来理解它们的功能。代码审查可以在这种情况下起到帮助作用。

软件开发反模式
我们都熟悉**GoF设计模式**,它们代表了软件设计中一般出现问题的可重用解决方案。它们是解决问题的模板,可以使用多次,并且它们代表了在设计应用程序时可以使用的最佳实践。
然而,还存在一些软件开发反模式。它们代表了常见的模式,但在实践中是无效或适得其反的。我们使用这些反模式,可能是因为缺乏经验或对这些模式是反模式并不了解,但它们也可能导致糟糕的设计或性能问题。
以下是一些常见的反模式列表:
- 上帝对象(God object):它执行许多功能,最好将这些功能分解成不同的对象。典型的上帝对象承担了许多职责和很多依赖关系。它控制许多其他类,并验证了单一职责原则。
- 单例模式(Singleton):这是最常用的设计模式之一。然而,它是一种反模式。它违反了信息隐藏原则,并且通常在应用程序中行为类似于静态数据,违反了良好的面向对象原则。
- Blob:在面向过程的设计中,最其他对象都是数据持有者或基本的功能实现者,只留下一个对象来处理大部分职责。
- 过于复杂的代码(Spaghetti Code)或大块的泥巴:这是最常见的反模式之一。这是一种几乎没有结构或模块的代码。通常,文件随机分布在随机的目录中,整个流程难以理解。并且一切都相互连接在一起。
- 金榔头、银子弹或模仿仪式(Cargo-cult):一个熟悉的技术应用于许多软件问题。这种解决方案通过通过教育、培训和书籍研究小组,扩大开发人员的知识,向他们介绍替代技术和方法。
- 过犹不及或可有可无(Gold plating):在超过增加价值的点上继续工作于某个任务或项目。
- 船锚(Boat Anchor)和无效代码(Dead code):这个概念与前一个类似,但不同之处在于,开发人员保留一些代码,因为它可能在以后需要。这会使得维护变得麻烦,因为代码包含了已经废弃的代码。
- 抽象逆转(Abstraction inversion):在这种情况下,我们不会公开函数或方法调用者所需的功能的实现,因此调用者需要重新实现相同的功能。例如,使用Java中的Vector来实现固定大小的列表,而不是使用数组(Vector在内部使用数组)。
- 接口膨胀(Interface bloat):使接口变得过于庞大,极其难以实现,并违反了单一职责。例如,在C#中实现IList:IsReadOnly、Count、Add、Remove、IndexOf等。
- 石化流动(Lava Flow):它指的是开发人员需要处理冗余或低质量的代码,但通常该代码能正常工作,因此将其删除是有风险的。这些问题通常源自初始阶段编写的旧代码,因此需要更多时间来优化或重构代码。
此外,还存在各种代码异味,如臃肿、面向对象滥用、阻碍变化、可有可无和耦合等。
“在错误的抽象上重复既定的结果” – Sandi Metz。

要了解更多关于这些反模式的信息,请查看以下链接:
奖励:每个程序员都应该了解的内存知识
请查看**Ulrich Drepper的这个精彩手稿**,它深入探讨了计算机内存系统及其对软件开发人员的影响。它讨论了以下内容:
- CPU缓存
- 虚拟内存
- 内存访问模式
- 性能工具
- 锁
- 多线程编程和内存
- 还有更多

内容由GeekAI网页翻译服务自动翻译完成。 原文地址:https://newsletter.techworld-with-milan.com/p/main-software-design-principles-you-should-know