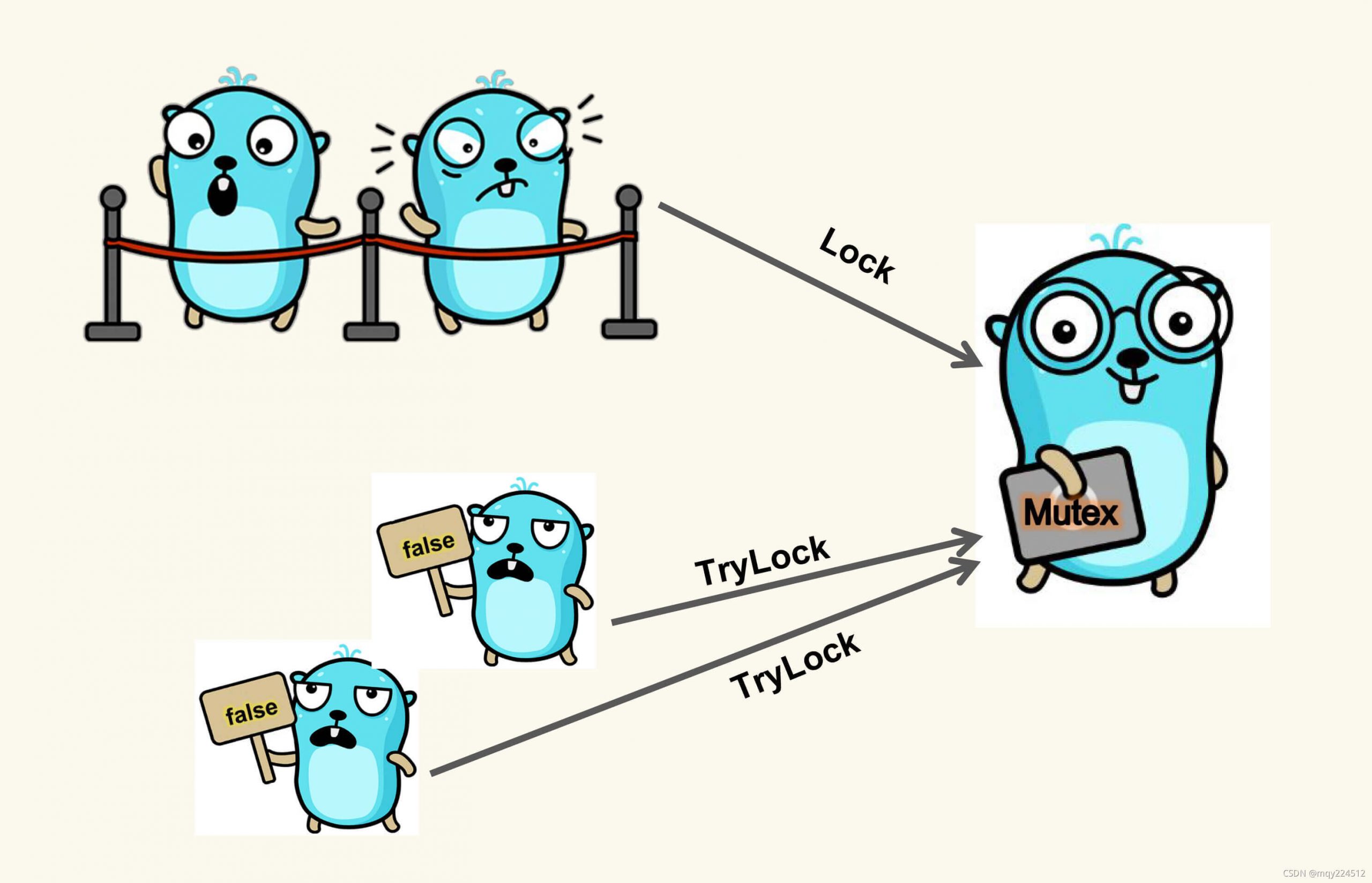
在上篇教程中我们已经用到了 sync 包提供的 Mutex 锁,锁的作用都是为了解决并发情况下共享数据的原子操作和最终一致性问题,在系统介绍 sync 包提供的各种锁之前,我们先来聊聊什么情况下需要用到锁。
竞态条件与同步机制
一旦数据被多个线程共享,那么就很可能会产生争用和冲突的情况,这种情况也被称为竞态条件(race condition),这往往会破坏共享数据的一致性。举个例子,同时有多个线程连续向同一个缓冲区写入数据块,如果没有一个机制去协调这些线程的写入操作的话,那么被写入的数据块就很可能会出现错乱。
比如,学院君的支付宝账户余额还有 500 元,代表银行自动转账的线程 A 正在向账户转入 3000 元本月工资,同时代表花呗自动扣费的线程 B 正在从账户余额扣除 2000 元还上个月的花呗账单。假设用 money 标识账户余额,那么初始值 money = 500,线程 A 的操作就等价于 money = money + 3000,线程 B 的操作就等价于 money = money - 2000,我们本来期望的结果是 money = 1500,但是现在线程 A 和线程 B 同时对 money 进行读取和写入,所以他们拿到的 money 都是 500,如果线程 A 后执行完毕,那么 money = 3500,如果线程 B 后执行完毕,那么 money = 0(扣除所有余额,花呗欠款 1500),这就出现了和预期结果不一致的现象,我们说,这个操作破坏了数据的一致性。
在这种情况下,我们就需要采取一些措施来协调它们对共享数据的修改,这通常就会涉及到同步操作。一般来说,同步的用途有两个,一个是避免多个线程在同一时刻操作同一个数据块,另一个是协调多个线程避免它们在同一时刻执行同一个代码块。但是目的是一致的,那就是保证共享数据原子操作和一致性。
由于这样的数据块和代码块的背后都隐含着一种或多种资源(比如存储资源、计算资源、I/O 资源、网络资源等等),所以我们可以把它们看做是共享资源。我们所说的同步其实就是在控制多个线程对共享资源的访问:一个线程在想要访问某一个共享资源的时候,需要先申请对该资源的访问权限,并且只有在申请成功之后,访问才能真正开始;而当线程对共享资源的访问结束时,它还必须归还对该资源的访问权限,若要再次访问仍需申请。
你可以把这里所说的访问权限想象成一块令牌,线程一旦拿到了令牌,就可以进入指定的区域,从而访问到资源,而一旦线程要离开这个区域了,就需要把令牌还回去,绝不能把令牌带走。或者我们把共享资源看作是有锁的资源,当某个线程获取到共享资源的访问权限后,给资源上锁,这样,其他线程就不能访问它,直到该线程执行完毕,释放锁,这样其他线程才能通过竞争获取对资源的访问权限,依次类推。
这样一来,我们就可以保证多个并发运行的线程对这个共享资源的访问是完全串行的,只要一个代码片段需要实现对共享资源的串行化访问,就可以被视为一个临界区(critical section),也就是我刚刚说的,由于要访问到资源而必须进入的那个区域。
在前面举的那个例子中,实现了账户余额写入操作的代码就组成了一个临界区。临界区总是需要通过同步机制进行保护的,否则就会产生竞态条件,导致数据不一致。
互斥锁
在 Go 语言中,可供我们选择的同步工具有很多。其中,最重要且最常用的同步工具当属互斥量(mutual exclusion,简称 mutex),sync 包中的 Mutex 就是与其对应的类型,该类型的值可以被称为互斥锁。一个互斥锁可以被用来保护一个临界区,我们可以通过它来保证在同一时刻只有一个 goroutine 处于该临界区之内,回到我们通过共享内存实现协程通信这篇教程中的示例:
package main
import (
"fmt"
"runtime"
"sync"
"time"
)
var counter int = 0
func addV2(a, b int, lock *sync.Mutex) {
lock.Lock()
c := a + b
counter++
fmt.Printf("%d: %d + %d = %d\n", counter, a, b, c)
lock.Unlock()
}
func main() {
start := time.Now()
lock := &sync.Mutex{}
for i := 0; i < 10; i++ {
go addV2(1, i, lock)
}
for {
lock.Lock()
c := counter
lock.Unlock()
runtime.Gosched() // 让出 CPU 时间片
if c >= 10 {
break
}
}
end := time.Now()
consume := end.Sub(start).Seconds()
fmt.Println("程序执行耗时(s):", consume)
}
每当有 goroutine 想进入临界区时,都需要先调用 lock.Lock() 对它进行锁定,并且,每个 goroutine 离开临界区时,都要及时地调用 lock.Unlock() 对它进行解锁,锁定和解锁操作分别通过互斥锁 sync.Mutex 的 Lock 和 Unlock 方法实现。使用互斥锁的时候有以下注意事项:
- 不要重复锁定互斥锁;
- 不要忘记解锁互斥锁,必要时使用
defer语句; - 不要对尚未锁定或者已解锁的互斥锁解锁;
- 不要在多个函数之间直接传递互斥锁。
读写锁
Mutex 是最简单的一种锁类型,同时也比较暴力,当一个 goroutine 获得了 Mutex 后,其他 goroutine 就只能乖乖等到这个 goroutine 释放该 Mutex,不管是读操作还是写操作都会阻塞,但其实我们知道为了提升性能,读操作往往是不需要阻塞的,因此 sync 包提供了 RWMutex 类型,即读/写互斥锁,简称读写锁,这是一个是单写多读模型。
sync.RWMutex 分读锁和写锁,会对读操作和写操作区分对待,在读锁占用的情况下,会阻止写,但不阻止读,也就是多个 goroutine 可同时获取读锁,读锁调用 RLock() 方法开启,通过 RUnlock 方法释放;而写锁会阻止任何其他 goroutine(无论读和写)进来,整个锁相当于由该 goroutine 独占,和 Mutex 一样,写锁通过 Lock 方法启用,通过 Unlock 方法释放,从 RWMutex 的底层实现看实际上是组合了 Mutex:
type RWMutex struct {
w Mutex
writerSem uint32
readerSem uint32
readerCount int32
readerWait int32
}
同样,使用 RWMutex 时,任何一个 Lock() 或 RLock() 均需要保证有对应的 Unlock() 或 RUnlock() 调用与之对应,否则可能导致等待该锁的所有 goroutine 处于阻塞状态,甚至可能导致死锁,比如我们可以通过 RWMutex 重构上面示例代码的锁,效果完全一样:
package main
import (
"fmt"
"runtime"
"sync"
"time"
)
var counter int = 0
func addV2(a, b int, lock *sync.RWMutex) {
c := a + b
lock.Lock()
counter++
fmt.Printf("%d: %d + %d = %d\n", counter, a, b, c)
lock.Unlock()
}
func main() {
start := time.Now()
lock := &sync.RWMutex{}
for i := 0; i < 10; i++ {
go addV2(1, i, lock)
}
for {
lock.RLock()
c := counter
lock.RUnlock()
runtime.Gosched()
if c >= 10 {
break
}
}
end := time.Now()
consume := end.Sub(start).Seconds()
fmt.Println("程序执行耗时(s):", consume)
}
条件变量
sync 包还提供了一个条件变量类型 sync.Cond,它可以和互斥锁或读写锁(以下统称互斥锁)组合使用,用来协调想要访问共享资源的线程。
不过,与互斥锁不同,条件变量 sync.Cond 的主要作用并不是保证在同一时刻仅有一个线程访问某一个共享资源,而是在对应的共享资源状态发生变化时,通知其它因此而阻塞的线程。条件变量总是和互斥锁组合使用,互斥锁为共享资源的访问提供互斥支持,而条件变量可以就共享资源的状态变化向相关线程发出通知,重在「协调」。
下面,我们来看看如何使用条件变量 sync.Cond。
sync.Cond 是一个结构体:
type Cond struct {
noCopy noCopy
// L is held while observing or changing the condition
L Locker
notify notifyList
checker copyChecker
}
提供了三个方法:
// 等待通知
func (c *Cond) Wait() {
c.checker.check()
t := runtime_notifyListAdd(&c.notify)
c.L.Unlock()
runtime_notifyListWait(&c.notify, t)
c.L.Lock()
}
// 单发通知
func (c *Cond) Signal() {
c.checker.check()
runtime_notifyListNotifyOne(&c.notify)
}
// 广播通知
func (c *Cond) Broadcast() {
c.checker.check()
runtime_notifyListNotifyAll(&c.notify)
}
我们可以通过 sync.NewCond 返回对应的条件变量实例,初始化的时候需要传入互斥锁,该互斥锁实例会赋值给 sync.Cond 的 L 属性:
locker := &sync.Mutex{}
cond := sync.NewCond(locker)
sync.Cond 主要实现一个条件变量,假设 goroutine A 执行前需要等待另外一个 goroutine B 的通知,那么处于等待状态的 goroutine A 会保存在一个通知列表,也就是说需要某种变量状态的 goroutine A 将会等待(Wait)在那里,当某个时刻变量状态改变时,负责通知的 goroutine B 会通过对条件变量通知的方式(Broadcast/Signal)来通知处于等待条件变量的 goroutine A,这样就可以在共享内存中实现类似「消息通知」的同步机制。
Signal
下面来看一个具体的示例。假设我们有一个读取器和一个写入器,读取器必须依赖写入器对缓冲区进行数据写入后,才可以从缓冲区中读取数据,写入器每次完成写入数据后,都需要通过某种通知机制通知处于阻塞状态的读取器,告诉它可以对数据进行访问,这种场景正好可以通过条件变量来实现:
package main
import (
"bytes"
"fmt"
"io"
"sync"
"time"
)
// 数据 bucket
type DataBucket struct {
buffer *bytes.Buffer //缓冲区
mutex *sync.RWMutex //互斥锁
cond *sync.Cond //条件变量
}
func NewDataBucket() *DataBucket {
buf := make([]byte, 0)
db := &DataBucket{
buffer: bytes.NewBuffer(buf),
mutex: new(sync.RWMutex),
}
db.cond = sync.NewCond(db.mutex.RLocker())
return db
}
// 读取器
func (db *DataBucket) Read(i int) {
db.mutex.RLock() // 打开读锁
defer db.mutex.RUnlock() // 结束后释放读锁
var data []byte
var d byte
var err error
for {
//每次读取一个字节
if d, err = db.buffer.ReadByte(); err != nil {
if err == io.EOF { // 缓冲区数据为空时执行
if string(data) != "" { // data 不为空,则打印它
fmt.Printf("reader-%d: %s\n", i, data)
}
db.cond.Wait() // 缓冲区为空,通过 Wait 方法等待通知,进入阻塞状态
data = data[:0] // 将 data 清空
continue
}
}
data = append(data, d) // 将读取到的数据添加到 data 中
}
}
// 写入器
func (db *DataBucket) Put(d []byte) (int, error) {
db.mutex.Lock() // 打开写锁
defer db.mutex.Unlock() // 结束后释放写锁
//写入一个数据块
n, err := db.buffer.Write(d)
db.cond.Signal() // 写入数据后通过 Signal 通知处于阻塞状态的读取器
return n, err
}
func main() {
db := NewDataBucket()
go db.Read(1) // 开启读取器协程
go func(i int) {
d := fmt.Sprintf("data-%d", i)
db.Put([]byte(d)) // 写入数据到缓冲区
}(1) // 开启写入器协程
time.Sleep(100 * time.Millisecond)
}
这里我们使用了读写互斥锁,在读取器里面使用读锁,在写入器里面使用写锁,并且通过 defer 语句释放锁,然后在锁保护的情况下,通过条件变量协调读写线程:在读线程中,当缓冲区为空的时候,通过 db.cond.Wait() 阻塞读线程;在写线程中,当缓冲区写入数据的时候通过 db.cond.Signal() 通知读线程继续读取数据。
执行上述示例代码,结果如下:
reader-1: data-1
Broadcast
上述示例代码只有一个读取器,一个写入器,如果都有多个呢?我们可以通过启动多个读写协程来模拟,此外,通知单个阻塞线程用 Signal 方法,通知多个阻塞线程需要使用 Broadcast 方法,按照这个思路,我们来改写上述示例代码如下:
package main
import (
"bytes"
"fmt"
"io"
"sync"
"time"
)
// 数据 bucket
type DataBucket struct {
buffer *bytes.Buffer //缓冲区
mutex *sync.RWMutex //互斥锁
cond *sync.Cond //条件变量
}
func NewDataBucket() *DataBucket {
buf := make([]byte, 0)
db := &DataBucket{
buffer: bytes.NewBuffer(buf),
mutex: new(sync.RWMutex),
}
db.cond = sync.NewCond(db.mutex.RLocker())
return db
}
// 读取器
func (db *DataBucket) Read(i int) {
db.mutex.RLock() // 打开读锁
defer db.mutex.RUnlock() // 结束后释放读锁
var data []byte
var d byte
var err error
for {
//每次读取一个字节
if d, err = db.buffer.ReadByte(); err != nil {
if err == io.EOF { // 缓冲区数据为空时执行
if string(data) != "" { // data 不为空,则打印它
fmt.Printf("reader-%d: %s\n", i, data)
}
db.cond.Wait() // 缓冲区为空,通过 Wait 方法等待通知,进入阻塞状态
data = data[:0] // 将 data 清空
continue
}
}
data = append(data, d) // 将读取到的数据添加到 data 中
}
}
// 写入器
func (db *DataBucket) Put(d []byte) (int, error) {
db.mutex.Lock() // 打开写锁
defer db.mutex.Unlock() // 结束后释放写锁
//写入一个数据块
n, err := db.buffer.Write(d)
db.cond.Broadcast() // 写入数据后通过 Broadcast 通知处于阻塞状态的读取器
return n, err
}
func main() {
db := NewDataBucket()
for i := 1; i < 3; i++ { // 启动多个读取器
go db.Read(i)
}
for j := 0; j < 10; j++ { // 启动多个写入器
go func(i int) {
d := fmt.Sprintf("data-%d", i)
db.Put([]byte(d)) // 写入数据到缓冲区
}(j)
time.Sleep(100 * time.Millisecond) // 每次启动一个写入器暂停100ms,让读取器阻塞
}
}
执行上述代码,打印结果如下:

可以看到,通过互斥锁+条件变量,我们可以非常方便的实现多个 Go 协程之间的通信。
原子操作
中断与原子操作
互斥锁是一个同步工具,它可以保证每一时刻进入临界区的协程只有一个;读写锁对共享资源的写操作和读操作区别看待,并消除了读操作之间的互斥;条件变量主要用于协调想要访问共享资源的那些线程,当共享资源的状态发生变化时,它可以被用来通知被互斥锁阻塞的线程,它既可以基于互斥锁,也可以基于读写锁(当然了,读写锁也是互斥锁,是对后者的一种扩展)。通过对互斥锁的合理使用,我们可以使一个 Go 协程在执行临界区中的代码时,不被其他的协程打扰,实现串行执行,不过,虽然不会被打扰,但是它仍然可能会被中断(interruption)。
所谓中断其实是 CPU 和操作系统级别的术语,并发执行的协程并不是真的并行执行,而是通过 CPU 的调度不断从运行状态切换到非运行状态,或者从非运行状态切换到运行状态,在用户看来,好像是「同时」在执行。我们把代码从运行状态切换到非运行状态称之为中断。中断的时机很多,比如任何两条语句执行的间隙,甚至在某条语句执行的过程中都是可以的,即使这些语句在临界区内也是如此。所以我们说互斥锁只能保证临界区代码的串行执行,不能保证这些代码执行的原子性,因为原子操作不能被中断。
原子操作通常是 CPU 和操作系统提供支持的,由于执行过程中不会中断,所以可以完全消除竞态条件,从而绝对保证并发安全性,此外,由于不会中断,所以原子操作本身要求也很高,既要简单,又要快速。Go 语言的原子操作也是基于 CPU 和操作系统的,由于简单和快速的要求,只针对少数数据类型的值提供了原子操作函数,这些函数都位于标准库代码包 sync/atomic 中。这些原子操作包括加法(Add)、比较并交换(Compare And Swap,简称 CAS)、加载(Load)、存储(Store)和交换(Swap)。
下面我们简单介绍下这些原子操作。
Go 语言中的原子操作
加减法
我们可以通过 atomic 包提供的下列函数实现加减法的原子操作,第一个参数是操作数对应的指针,第二个参数是加/减值:

虽然这些函数都是以 Add 前缀开头,但是对于减法可以通过传递负数实现,不过对于后三个函数,由于操作数类型是无符号的,所以无法显式传递负数来实现减法。比如我们测试下 AddInt32 函数:
var i int32 = 1
atomic.AddInt32(&i, 1)
fmt.Println("i = i + 1 =", i)
atomic.AddInt32(&i, -1)
fmt.Println("i = i - 1 =", i)
上述代码打印结果如下:
i = i + 1 = 2
i = i - 1 = 1
比较并交换
比较并交换相关的原子函数如下,第一个参数是操作数对应的指针,第二、三个参数是待比较和交换的旧值和新值:

这些函数会在交换之前先判断 addr 地址中的值是否与 old 相等,如果不相等则返回 false,否则将其替换成 new:
var a int32 = 1
var b int32 = 2
var c int32 = 2
atomic.CompareAndSwapInt32(&a, a, b)
atomic.CompareAndSwapInt32(&b, b, c)
fmt.Println("a, b, c:", a, b, c)
上述代码的打印结果是:
a, b, c: 2 2 2
加载
加载相关的原子操作函数如下,这些操作函数仅传递一个参数,即待操作数对应的指针,并且有一个返回值,返回传入指针指向的值:

这里的「原子性」指的是当读取该指针指向的值时,CPU 不会执行任何其它针对此值的读写操作。例如,我们可以这样调用 LoadInt32 函数:
var x int32 = 100
y := atomic.LoadInt32(&x)
fmt.Println("x, y:", x, y)
存储
存储相关的原子函数如下所示,第一个参数表示待操作变量对应的指针,第二个参数表示要存储到待操作变量的数值:

该操作可以看作是加载操作的逆向操作,一个用于读取,一个用于写入,通过上述原子函数存储数值的时候,不会出现存储流程进行到一半被中断的情况,比如我们可以通过 StoreInt32 函数改写上述设置 y 变量的操作代码:
var x int32 = 100
var y int32
atomic.StoreInt32(&y, atomic.LoadInt32(&x))
fmt.Println("x, y:", x, y)
打印结果和之前完全一致。
交换
交换和比较并交换看起来有点类似,但是交换不关心待操作数的旧值,不管旧值和新值是否相等,都会通过新值替换旧值,不过,交换函数有一个返回值,会返回旧值:

示例代码如下:
var j int32 = 1
var k int32 = 2
j_old := atomic.SwapInt32(&j, k)
fmt.Println("old,new:", j_old, j)
打印结果为:
old,new: 1 2
原子类型
为了扩大原子操作的适用范围,Go 语言在 1.4 版本发布的时候向 sync/atomic 包中添加了一个新的类型 Value,此类型的值相当于一个容器,可以被用来「原子地」存储和加载任意的值:
type Value struct {
v interface{}
}
atomic.Value 类型是开箱即用的,我们声明一个该类型的变量(以下简称原子变量)之后就可以直接使用了。这个类型使用起来很简单,它只有 Store 和 Load 两个指针方法,这两个方法都是原子操作:
var v atomic.Value
v.Store(100)
fmt.Println("v:", v.Load())
不过,虽然简单,但还是有一些需要注意的地方。首先,存储值不能是 nil;其次,我们向原子类型存储的第一个值,决定了它今后能且只能存储该类型的值。如果违背这两条,编译时会抛出 panic。
基于消息传递实现协程通信
前面我们说,除了共享内存之外,还可以通过消息传递来实现协程通信,Go 语言本身的编程哲学也是「Don’t communicate by sharing memory, share memory by communicating」,所以实际上,我们在 Go 语言并发编程实践中,更多使用的都是基于消息传递的方式实现协程之间的通信。
在消息传递机制中,每个协程是独立的个体,并且都有自己的变量,与共享内存不同的是,在不同协程间这些变量不共享,每个协程的输入和输出都只有一种方式,那就是消息,这有点类似于进程:每个进程都是独立的,不会被其他进程打扰,不同进程间靠消息来通信,它们不会共享内存。
下篇教程,我们就来系统介绍 Go 语言是如何基于消息传递实现协程间通信的。



学院君,后面的文章还更新吗?
更新 最迟下周开始更新
学院君,催更啦
后面的文章还更新嘛
催更催更!写的这么好,得跟着学下去才行啊