
字符串
基本使用
在 Go 语言中,字符串是一种基本类型,默认是通过 UTF-8 编码的字符序列,当字符为 ASCII 码时则占用 1 个字节,其它字符根据需要占用 2-4 个字节,比如中文编码通常需要 3 个字节。
声明和初始化
字符串的声明和初始化非常简单,举例如下:
var str string // 声明字符串变量 str = "Hello World" // 变量初始化 str2 := "你好,学院君" // 也可以同时进行声明和初始化
格式化输出
还可以通过 Go 语言内置的 len() 函数获取指定字符串的长度,以及通过 fmt 包提供的 Printf 进行字符串格式化输出:
fmt.Printf("The length of \"%s\" is %d \n", str, len(str))
fmt.Printf("The first character of \"%s\" is %c.\n", str, ch)
转义字符
Go 语言的字符串不支持单引号,只能通过双引号定义字符串字面值,如果要对特定字符进行转义,可以通过 \ 实现,就像我们上面在字符串中转义双引号和换行符那样,常见的需要转义的字符如下所示:
\n:换行符\r:回车符\t:tab 键\u或 \U :Unicode 字符\\:反斜杠自身
所以,上述打印代码输出结果为:
The length of "Hello world" is 11 The first character of "Hello world" is H.
除此之外,你可以通过如下方式在字符串中包含 ":
label := `Search results for "Golang":`
多行字符串
对于多行字符串,也可以通过 ` 构建:
results := `Search results for "Golang":
- Go
- Golang
Golang Programming
`
fmt.Printf("%s", results)
打印结果如下:
Search results for "Golang": - Go - Golang - Golang Programming
当然,使用 + 连接符也是可以的:
results := "Search results for \"Golang\":\n" +
"- Go\n" +
"- Golang\n" +
"- Golang Programming\n"
fmt.Printf("%s", results)
打印结果是一样的,但是要多输入不少字符,也不如上一种实现优雅。
不可变值类型
虽然可以通过数组下标方式访问字符串中的字符:
ch := str[0] // 取字符串的第一个字符
但是和数组不同,在 Go 语言中,字符串是一种不可变值类型,一旦初始化之后,它的内容不能被修改,比如看下面这个例子:
str := "Hello world" str[0] = 'X' // 编译错误
编译器会报类似如下的错误:
cannot assign to str[0]
字符编码
Go 语言中字符串默认是 UTF-8 编码的 Unicode 字符序列,所以可以包含非 ANSI 字符,比如「Hello, 学院君」可以出现在 Go 代码中。
但需要注意的是,如果你的 Go 代码需要包含非 ANSI 字符,保存源文件时请注意编码格式必须选择 UTF-8。特别是在 Windows 下一般编辑器都默认保存为本地编码,比如中国地区可能是 GBK 编码而不是 UTF-8,如果没注意到这点在编译和运行时就会出现一些意料之外的情况。
字符串的编码转换是处理文本文档(比如 TXT、XML、HTML 等)时非常常见的需求,不过 Go 语言默认仅支持 UTF-8 和 Unicode 编码,对于其他编码,Go 语言标准库并没有内置的编码转换支持。所幸的是我们可以很容易基于 iconv 库包装一个,这里有一个开源项目可供参考:https://github.com/qiniu/iconv。
字符串操作
字符串连接
Go 内置提供了丰富的字符串函数,常见的操作包含连接、获取长度和指定字符,获取长度和指定字符前面已经介绍过,字符串连接只需要通过 + 连接符即可:
str = str + ", 学院君" str += ", 学院君" // 上述语句也可以简写为这样,效果完全一样
另外,还有一点需要注意的是如果字符串长度较长,需要换行,则 + 连接符必须出现在上一行的末尾,否则会报错:
str = str +
", 学院君"
字符串切片
在 Go 语言中,可以通过字符串切片实现获取子串的功能:
str := "hello, world"
str1 := str[:5] // 获取索引5(不含)之前的子串
str2 := str[7:] // 获取索引7(含)之后的子串
str3 := str[0:5] // 获取从索引0(含)到索引5(不含)之间的子串
fmt.Println("str1:", str1)
fmt.Println("str2:", str2)
fmt.Println("str3:", str3)
Go 切片区间可以对比数学中的区间概念来理解,它是一个左闭右开的区间,比如上述 str[0:5] 对应到字符串元素的区间是 [0,5),str[:5] 对应的区间是 [0,5)(数组索引从 0 开始),str[7:] 对应的区间是 [7:len(str)](这是闭区间,是个例外,因为没有指定区间结尾)。
所以,上述代码打印结果如下:
str1: hello str2: world str3: hello
综上所述,字符串切片通过 : 连接的起始点和结束点索引对字符串进行切片,冒号之前的数字代表起始点,为空表示从 0 开始,之后的数字代表结束点,为空表示到字符串最后,而不是子串的长度。所以 str[:] 会打印出完整的字符串来。
此外 Go 字符串也支持字符串比较、是否包含指定字符/子串、获取指定子串索引位置、字符串替换、大小写转换、trim 等操作,更多操作 API,请参考标准库 strings 包,这里就不一一展示了。
字符串遍历
Go 语言支持两种方式遍历字符串。
一种是以字节数组的方式遍历:
str := "Hello, 世界"
n := len(str)
for i := 0; i < n; i++ {
ch := str[i] // 依据下标取字符串中的字符,ch 类型为 byte
fmt.Println(i, ch)
}
这个例子的输出结果为:
0 72 1 101 2 108 3 108 4 111 5 44 6 32 7 228 8 184 9 150 10 231 11 149 12 140
可以看出,这个字符串长度为 13,尽管从直观上来说,这个字符串应该只有 9 个字符。这是因为每个中文字符在 UTF-8 中占 3 个字节,而不是 1 个字节。
另一种是以 Unicode 字符遍历:
str := "Hello, 世界"
for i, ch := range str {
fmt.Println(i, ch) // ch 的类型为 rune
}
输出结果为:
0 72 1 101 2 108 3 108 4 111 5 44 6 32 7 19990 10 30028
这个时候,打印的就是 9 个字符了,因为以 Unicode 字符方式遍历时,每个字符的类型是 rune,而不是 byte。
看到这里可能你有点懵,会好奇 Go 底层到底是如何存储字符串的,为什么不同遍历方式获取的结果不同呢?下面学院君就来给大家简单掰扯掰扯。
底层字符类型
Go 语言对字符串中的单个字符进行了单独的类型支持,在 Go 语言中支持两种字符类型:
- 一种是
byte,代表 UTF-8 编码中单个字节的值(它也是uint8类型的别名,两者是等价的,因为正好占据 1 个字节的内存空间); - 另一种是
rune,代表单个 Unicode 字符(它也是int32类型的别名,因为正好占据 4 个字节的内存空间。关于rune相关的操作,可查阅 Go 标准库的 unicode 包)。
UTF-8 和 Unicode 的区别
说到这里,我们需要区分 UTF-8 和 Unicode 的区别。
Unicode 是一种字符集,囊括了目前世界上所有语言的所有字符,与之类似的术语还有 ASCII 字符集(仅包含 256 个字符)、ISO 8859-1 字符集等(包含所有西方拉丁字母),广义的 Unicode 既包含了字符集,也包含了编码规则,比如 UTF-8、UTF-16、UTF8MB4、GBK 等。
因此 UTF-8 是 Unicode 字符集的实现方式之一,它会将 Unicode 字符以某种方式进行编码。在具体实现时,UTF-8 是一种变长的编码规则,从 1~4 个字节不等,比如英文字符是 1 个字节,中文字符是 3 个字节。通过 UTF-8 编码的 Unicode 字符以最大长度 4 个字节作为单个字符固定占据的内存空间,在 Go 语言中可以通过 unicode/utf8 包进行 UTF-8 和 Unicode 之间的转换。
所以如果从 Unicode 字符集的视角看,字符串的每个字符都是一个字符的独立单元,但如果从 UTF-8 编码的视角看,一个字符可能是由多个字节编码而来的。
我们通过 len 函数获取到的是字符串的字节长度,再据此通过字符数组的方式遍历字符串时,是以 UTF-8 编码的角度切入的;而当我们通过 range 关键字遍历字符串时,又是从 Unicode 字符集的角度切入的,如此一来就得到了不同的结果。
出于简化语言的考虑,Go 语言的多数 API 都假设字符串为 UTF-8 编码。
将 Unicode 编码转化为可打印字符
如果你想要将 Unicode 字符编码转化为对应的字符,可以使用 string 函数进行转化::
str := "Hello, 世界"
for i, ch := range str {
fmt.Println(i, string(ch))
}
对应的打印结果如下:
0 H 1 e 2 l 3 l 4 o 5 , 6 7 世 10 界
UTF-8 编码不能这样转化,英文字符没问题,因为一个英文字符就是一个字节,中文字符则会乱码,因为一个中文字符编码需要三个字节,转化单个字节会出现乱码。

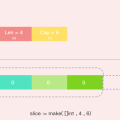



最上面的
ch := str[0] // 取字符串的第一个字符
这个ch是不是没了 院长
byte 和 rune不是 int8 和 int32 吗
uint8 和 int32
utf8 是Unicode 字符集的具体编码实现,上面 “将 Unicode 编码转化为可打印字符” 应该是rune 字符串遍历方式可以转化,但字节数组方式不能转化,而不是utf8编码方式不能转化吧