

通过上一课程,我们了解到生成式人工智能如何改变技术领域,大型语言模型(LLMs)是如何工作的,以及像我们的初创公司这样的企业如何将它们应用于使用案例并实现增长!在这一章中,我们将比较和对比不同类型的大型语言模型,以了解它们的优缺点。
我们初创公司的下一步是探索现有的大型语言模型(LLMs)领域,并了解哪些模型适用于我们的使用案例。
介绍
本课程将涵盖以下内容:
- 目前领域中不同类型的LLMs。
- 在Azure中测试、迭代和比较不同模型以适应您的使用案例。
- 如何部署LLM。
学习目标
完成本课程后,您将能够:
- 选择适合您使用案例的正确模型。
- 理解如何测试、迭代和提高模型的性能。
- 了解企业如何部署模型。
了解不同类型的LLM
大型语言模型(LLMs)可以根据其架构、训练数据和使用案例进行多种分类。了解这些差异将帮助我们的初创公司选择适合场景的正确模型,并了解如何测试、迭代和提高性能。
有许多不同类型的LLM模型,您选择的模型取决于您希望将它们用于什么目的、您的数据、您准备支付的费用等等。
根据您希望使用模型进行文本、音频、视频、图像生成等的目的,您可能会选择不同类型的模型。
- 音频和语音识别。对于这个目的,想要模型是一个很好的选择,因为它们是通用目标并且针对语音识别。它经过多样化音频的训练,可以进行多语种语音识别。例如,您可以使用从较便宜但功能强大的模型curie到更昂贵但性能优越的davinci型模型的各种模型。了解有关Whisper型模型的更多信息。
- 图像生成。对于图像生成,DALL-E和Midjourney是两个非常知名的选择。DALL-E由Azure OpenAI提供。在这里阅读更多关于DALL-E的信息,还可以在本课程的第9章中了解更多。
- 文本生成。大多数模型都是针对文本生成训练的,您可以从GPT-3.5到GPT-4中选择各种选择。它们的成本不同,其中GPT-4是最昂贵的。值得在Azure Open AI playground中研究一下,评估哪些模型最适合您的需求。
选择一个模型意味着您获得了一些基本功能,但这可能还不够。通常,您具有特定于公司的数据,需要一些方式来告诉LLM。在即将到来的部分中,有几种不同的选择方法。
基础模型与LLMs
术语基础模型由斯坦福大学研究人员提出并定义为满足一些标准的AI模型,例如:
- 它们使用无监督学习或自监督学习进行训练,意味着它们在未标记的多模态数据上进行训练,并且不需要人工注释或标记数据的训练过程。
- 它们是非常大的模型,基于训练在数十亿个参数上的非常深的神经网络。
- 它们通常用作其他模型的“基础”,这意味着它们可用作其他模型的起点,可以通过微调来构建其他模型。
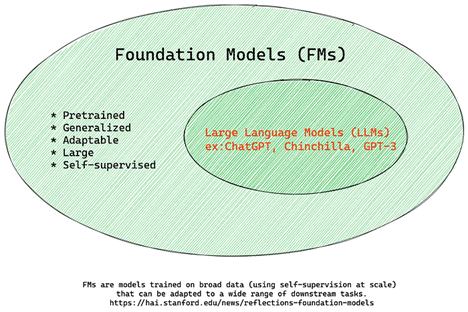
图像来源:基础模型和大型语言模型的重要指南 | Babar M Bhatti | Medium
为了进一步明确这个区别,让我们以ChatGPT为例。为了构建ChatGPT的第一个版本,OpenAI使用了一个名为GPT-3.5的模型作为基础模型。这意味着OpenAI使用一些与聊天相关的数据创建了GPT-3.5的一个调优版本,该版本在聊天场景(如聊天机器人)中表现良好。
图像来源:2108.07258.pdf (arxiv.org)
开源模型与专有模型
将LLMs分类为开源或专有的另一种方法。
开源模型是由公司或研究社区提供的所有人均可以使用的模型。这些模型通常可以进行检查、修改和定制,以适应LLMs的各种使用案例。然而,它们并不总是针对生产使用进行优化,并且可能不如专有模型性能优越。此外,开源模型的资金可能有限,可能无法长期维护,或者可能无法使用最新的研究进行更新。常见的开源模型示例包括Alpaca,Bloom和LLaMA。
专有模型是由公司拥有并且不向公众提供的模型。这些模型通常经过针对生产使用进行优化。但是,它们不允许进行检查、修改或定制以适应不同的使用案例。此外,它们并非总是免费提供,并可能需要订阅或付费使用。此外,用户无法控制用于训练模型的数据,这意味着他们应该委托模型所有者确保数据隐私和负责任地使用AI。常见的专有模型示例包括OpenAI模型,Google Bard或Claude 2。
嵌入对比图像生成对比文本和代码生成
LLMs还可以根据它们生成的输出进行分类。
嵌入是一组可以将文本转换为数字形式的模型,称为嵌入,嵌入是输入文本的数值表示。嵌入使得机器更容易理解单词或句子之间的关系,并且可以被其他模型(例如分类模型或对数数据性能更好的聚类模型)作为输入使用。嵌入模型通常用于迁移学习,其中一个模型针对存在大量数据的代理任务进行构建,然后可以将模型权重(嵌入)重新用于其他下游任务。此类别的一个例子是OpenAI嵌入。
图像生成模型是生成图像的模型。这些模型通常用于图像编辑、图像合成和图像翻译。图像生成模型通常在大型图像数据集上进行训练,例如LAION-5B,可以用于生成新图像或使用修补、超分辨率和着色技术编辑现有图像。示例包括DALL-E-3和稳定扩散模型。
文本和代码生成模型是生成文本或代码的模型。这些模型通常用于文本摘要、翻译和问答。文本生成模型通常在大量文本数据集上进行训练,例如BookCorpus,可以用于生成新文本或回答问题。代码生成模型(如CodeParrot)通常在大量代码数据集(如GitHub)上进行训练,可以用于生成新代码或修复现有代码中的错误。

编码器-解码器对解码器
为了讨论LLMs的不同架构类型,让我们使用一个类比。
想象一下,您的经理给您提了一个写测验的任务。您有两个同事;一个负责创建内容,另一个负责审核。
内容创建者类似于只解码器模型,他们可以查看主题并查看您已经写过的内容,然后根据此内容编写课程。他们非常擅长撰写引人入胜和有用的内容,但在理解主题和学习目标方面不是特别擅长。解码器模型的一些示例是GPT系列模型,如GPT-3。
审核者类似于仅编码器模型,他们查看编写的课程和答案,注意它们之间的关系并理解上下文,但他们不能很好地生成内容。编码器模型的一个示例是BERT。
想象一下,我们也可以同时有一个人既可以创建又可以审核测验,这就是编码器-解码器模型。一些示例包括BART和T5。
服务与模型
现在,让我们讨论服务和模型之间的区别。服务是云服务提供商提供的一种产品,通常是模型、数据和其他组件的组合。模型是服务的核心组件,通常是基础模型,如LLMs。
服务通常针对生产使用进行优化,通常比模型更易于使用,通过图形用户界面操作。然而,服务并非总是免费提供的,可能需要订阅或付款才能使用,作为使用服务所有者的设备和资源的交换,实现费用优化和易于扩展。服务的一个例子是Azure OpenAI服务,该服务提供按使用量付费的费率计划,意味着用户根据使用服务的量按比例收费。此外,Azure OpenAI服务还提供企业级的安全性和负责任的AI框架,以增强模型的功能。
模型只是神经网络,带有参数、权重和其他信息。允许公司在本地运行模型,但需要购买设备、建立结构以实现扩展,并购买许可证或使用开源模型。像LLaMA这样的模型可供使用,需要计算能力来运行模型。
如何在Azure上测试和迭代不同模型以了解性能
一旦我们的团队探索了当前的LLMs领域,并确定了一些适合他们场景的优秀候选模型,下一步是在他们的数据和工作负载上进行测试。这是一个通过实验和测量进行的迭代过程。我们在前面的段落中提到的大多数模型(OpenAI模型、像Llama2这样的开源模型和Hugging Face转换器)都可以在Azure机器学习平台的基础模型目录中找到。
Azure机器学习是一种云服务,专为数据科学家和机器学习工程师设计,可在一个平台上管理整个机器学习生命周期(训练、测试、部署和处理MLOps)。机器学习工作室为该服务提供了图形用户界面,并使用户能够:
- 在目录中找到感兴趣的基础模型,通过任务、许可证或名称进行过滤。还可以导入尚未包含在目录中的新模型。
- 查看模型说明卡片,包括详细说明和代码示例,并使用示例推理小部件进行测试,提供示例提示以测试结果。
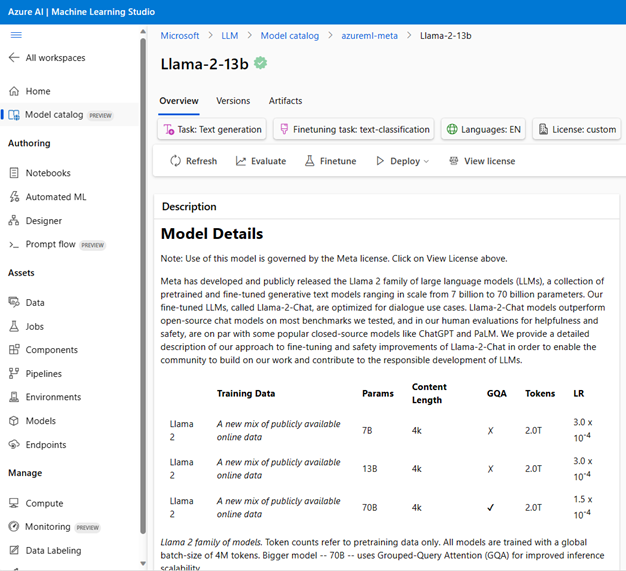
- 使用目标评估指标对模型的性能进行评估,在特定的工作负载和一组特定的输入数据上进行评估。
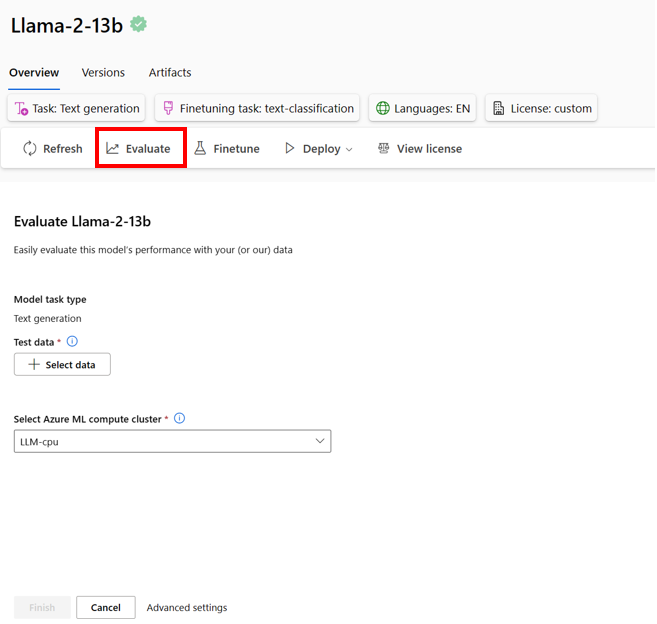
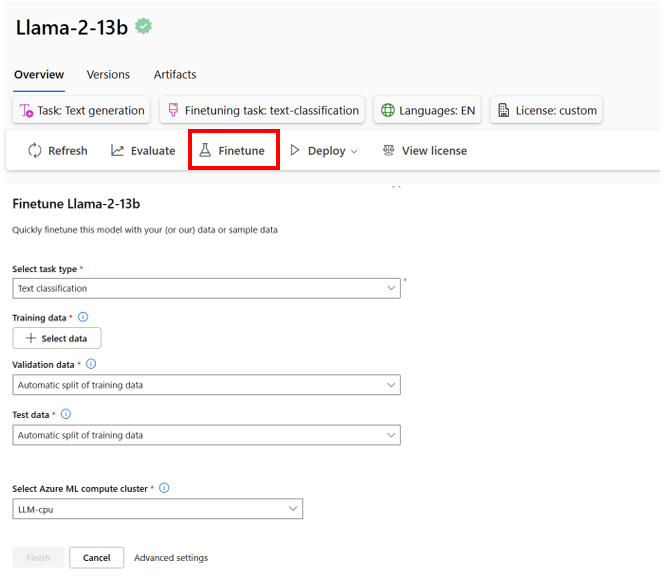
- 在自定义训练数据上对模型进行微调,以改进特定工作负载中的模型性能,利用Azure机器学习的实验和跟踪功能。
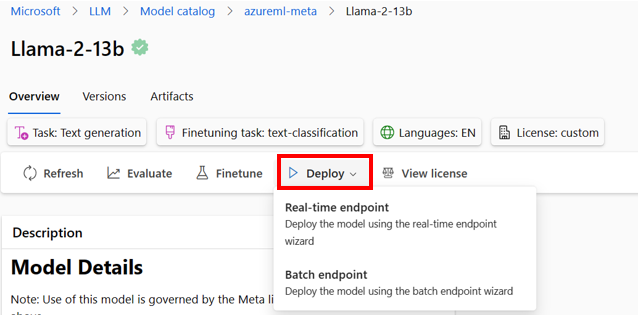
- 将原始的预先训练模型或微调版本部署到远程实时推理或批处理端点,以便应用程序消费。
改进LLM结果
我们与初创团队探索了不同类型的LLMs和一个云平台(Azure机器学习),使我们能够比较不同模型,评估它们在测试数据上的性能,提高性能并在推理端点上部署它们。
但是,他们什么时候应该考虑微调模型而不是使用预训练模型?还有其他方法可以改进特定工作负载上的模型性能吗?
业务可以使用几种方法来获得LLM所需的结果,您可以选择具有不同训练程度的不同类型的模型
在生产中部署LLM,具有不同的复杂性、成本和质量水平。下面是一些不同的方法:
- 具有上下文的提示工程。这个思路是在提示时提供足够的上下文,以确保您获得所需的回答。
- 检索增强生成,RAG。您的数据可能存在于数据库或Web端点中,为了确保在提示时包含此数据或其子集,您可以获取相关数据,并将其作为用户提示的一部分。
- 微调模型。在这种情况下,您可以进一步对自己的数据进行训练,从而使模型更加准确和适应您的需求,但可能成本较高。
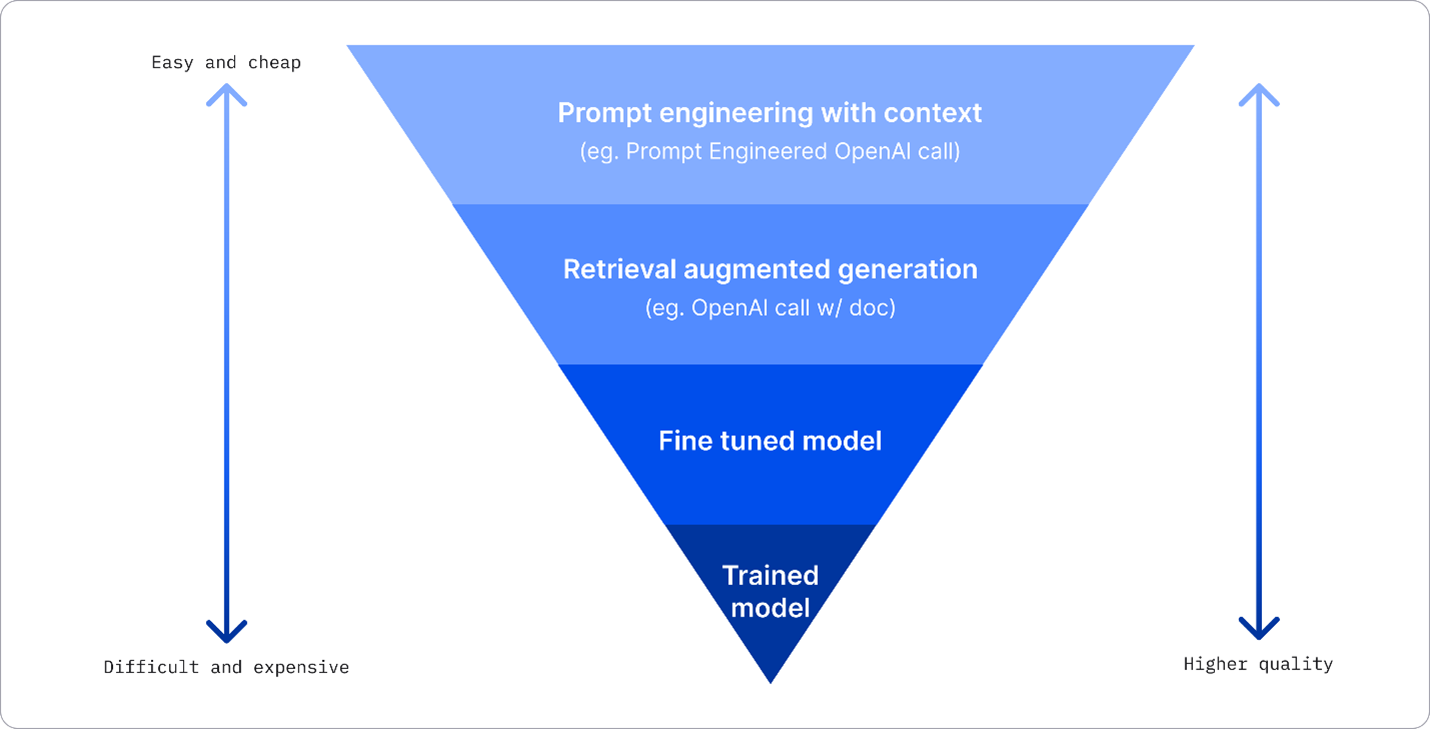
图像来源:Four Ways that Enterprises Deploy LLMs | Fiddler AI Blog
具有上下文的提示工程
预训练的LLMs在广义自然语言任务上表现非常好,即使通过短提示(例如一个要完成的句子或一个问题)调用它们也是如此,即所谓的“零次学习”。
然而,用户能够通过提供详细的请求和示例-上下文-来构建查询,这样答案将更精确,更符合用户的期望。在这种情况下,我们谈论的是“一次学习”(如果提示只包含一个示例)或“几次学习”(如果提示包含多个示例)。 具有上下文的提示工程是最具成本效益的方法。
检索增强生成(RAG)
LLMs的局限性在于它们只能使用训练过程中使用的数据来生成答案。这意味着它们不知道训练过程之后发生的事实,并且无法访问非公开信息(如公司数据)。检索增强生成是一种通过以文档块的形式在提示上下文中添加外部数据的技术,来克服这一限制,同时考虑到提示长度限制。这是通过向量数据库工具(例如Azure向量搜索)支持的,该工具从多个预定义数据源中检索有用的块,并将其添加到提示上下文中。
这种技术在业务没有足够的数据、时间或资源来微调LLMs但仍希望在特定工作负载上提高性能并降低幻觉(即对现实或有害内容的迷恋)的风险时非常有用。
微调模型
微调是一种利用迁移学习来“调整”模型以适应下游任务或解决特定问题的过程。与少量学习和RAG不同,它会生成一个新的模型,具有更新的权重和偏差。它需要一组训练示例,其中包含单个输入(提示)及其关联的输出(完成)。 如果:
- 使用微调模型。业务希望使用微调低性能的模型(如嵌入模型)而不是高性能模型,从而获得更具成本效益和更快的解决方案。
- 考虑延迟。延迟对于特定使用案例很重要,因此无法使用非常长的提示,或者应从模型学习的示例数量与提示长度限制不符合。
- 保持最新。业务拥有大量高质量数据和地面真实标签,并且拥有维护此数据的资源,以便将其随时间保持最新。
这将是优先考虑的方法。
训练模型
从头开始训练LLMs无疑是最困难和最复杂的方法,需要大量的数据、熟练的资源和适当的计算能力。只有在具有特定于领域的使用案例和大量面向领域的数据的场景下才应考虑此选项。
知识检查
哪种方法可以改进LLM的完成结果?
- 具有上下文的提示工程
- RAG
- 微调模型
答案是:3,如果您有足够的时间和资源和高质量的数据,微调是更好的选择以保持最新。但是,如果您想要改进并且时间不足,首先考虑RAG会更有价值。
🚀 挑战]
进一步阅读关于如何使用RAG来帮助您的业务。
干得好,继续学习吧
想要了解更多关于不同生成式AI概念的知识吗?请访问持续学习页面,找到其他关于这个主题的优质资源。
前往第3课,我们将学习如何负责任地使用生成式AI!
本文由极客智坊网页翻译服务自动翻译完成:




